
مقایسه تجربی عملکرد الگوریتم های مرتب سازی Quick Sort، Merge Sort، Heap Sort و Tim Sort روی داده های تصادفی
چکیده
مرتب سازی یکی از عملیات های پایه ای در علوم کامپیوتر است که در بسیاری از کاربردها نظیر پایگاه داده ها، سیستم های اطلاعاتی، و پردازش داده های عظیم نقش کلیدی دارد. انتخاب الگوریتم مرتب سازی مناسب می تواند تأثیر مستقیم بر کارایی و زمان پاسخ دهی سیستم داشته باشد. در این مقاله، چهار الگوریتم مشهور مرتب سازی شامل Quick Sort، Merge Sort، Heap Sort و Tim Sort (الگوریتم پیش فرض پایتون) از نظر زمان اجرا مورد ارزیابی تجربی قرار گرفته اند. داده های آزمایش شامل آرایه هایی با اندازه های ۱۰۰، ۵۰۰، ۱۰۰۰، ۵۰۰۰ و ۱۰۰۰۰ عنصر صحیح تصادفی بودند. نتایج حاکی از آن است که الگوریتم Tim Sort در تمامی اندازه ها سریع ترین عملکرد را دارد (برای آرایه ۱۰۰۰۰ عنصری حدود ۱.۲۵ میلی ثانیه). Heap Sort با ۳.۰۹ میلی ثانیه در جایگاه دوم قرار می گیرد و Quick Sortو Merge Sort به ترتیب با ۱۸.۳۲ و ۱۹.۷۹ میلی ثانیه کندترین هستند. همچنین تأثیر انتخاب pivot در Quick Sort و هزینه کپی حافظه در Merge Sort مورد بحث قرار گرفته است. این یافته ها راهنمایی عملی برای توسعه دهندگان نرم افزار در انتخاب الگوریتم مناسب بر اساس حجم داده و محدودیت های سخت افزاری فراهم می کند.
کلیدواژه ها:
الگوریتم مرتب سازی، Quick Sort، Merge Sort، Heap Sort، Tim Sort، تحلیل عملکرد تجربی، داده های تصادفی.
۱. مقدمه
امروزه حجم داده های تولید شده در سیستم های کامپیوتری به سرعت در حال افزایش است. عملیات مرتب سازی به عنوان یکی از پرمصرف ترین عملیات ها در الگوریتم های جستجو، فشرده سازی، و یادگیری ماشین شناخته می شود. از این رو، سال هاست که محققان الگوریتم های متنوعی با ویژگی های متفاوت ارائه داده اند. در میان آن ها، Quick Sort به دلیل سرعت بالا در حالت میانگین، Merge Sort به دلیل پیچیدگی پایدار O(n log n)) و Heap Sort به دلیل مرتب سازی درجا (in-place) محبوبیت دارند. همچنین، زبان پایتون از الگوریتم ترکیبی Tim Sort به عنوان تابع داخلی sorted استفاده می کند که برای داده های نیمه مرتب بهینه شده است.
هدف اصلی این مقاله، مقایسه تجربی این چهار الگوریتم روی داده های تصادفی با اندازه های مختلف است. برخلاف تحلیل های نظری صرف که فقط پیچیدگی زمانی را با نماد (O) بزرگ بیان می کنند، در این پژوهش زمان واقعی اجرا در یک محیط مشخص اندازه گیری شده است. این کار به درک بهتر «تفاوت عملی» الگوریتم ها کمک می کند.
۲. کارهای مرتبط
تحلیل نظری الگوریتم های مرتب سازی در کتب مرجعی مانند [Cormen et al., 2009] به تفصیل آمده است. همچنین مقایسه های تجربی متعددی در منابع مختلف انجام شده است. برای مثال، مطالعه [McIlroy et al., 1993] نشان داد که Quick Sort با انتخاب تصادفی pivot می تواند عملکرد بهتری نسبت به نسخه های قطعی داشته باشد. در سال ۲۰۰۲، [Auguston] مقایسه ای بین الگوریتم های مرتب سازی در زبان جاوا انجام داد و نشان داد که Merge Sort برای داده های بزرگ مناسب تر است. Tim Sort که توسط Tim Peters در سال ۲۰۰۲ برای پایتون طراحی شد، بعدها در جاوا (برای مرتب سازی اشیاء) و اندروید نیز به کار گرفته شد. یک مطالعه تجربی در سال ۲۰۱۸ [Nayak & Padhy] نشان داد که Tim Sort در داده های تصادفی و نیمه مرتب از سایر الگوریتم ها بهتر عمل می کند. با این حال، بیشتر این مطالعات روی داده های بسیار بزرگ (میلیون ها عنصر) متمرکز بوده اند. در این مقاله، ما روی محدوده داده های کوچک تا متوسط (۱۰۰ تا ۱۰۰۰۰) تمرکز کرده ایم که در بسیاری از برنامه های کاربردی روزمره دیده می شود.
۳. معرفی الگوریتم های مرتب سازی
۳.۱. Quick Sort
Quick Sort با انتخاب یک عنصر محوری (pivot) آرایه را به سه بخش: عناصر کوچک تر از pivot، مساوی با pivot، و بزرگ تر از pivot تقسیم کرده و به طور بازگشتی هر بخش را مرتب می کند. پیچیدگی میانگین (O(n log n))، بدترین حالت (هنگامی که آرایه از قبل مرتب باشد و pivot از انتها انتخاب شود) (O(n^2) ) است. در پیاده سازی ما، pivot از وسط آرایه برگزیده شده تا احتمال بدترین حالت کاهش یابد.
۳.۲. Merge Sort
Merge Sort آرایه را به دو نیمه تقسیم، هر نیمه را بازگشتی مرتب، سپس دو نیمه را ادغام می کند. پیچیدگی همیشه (O(n log n) ) است، اما به حافظه اضافی (O(n)) نیاز دارد. مزیت آن پایداری (stability) و رفتار قابل پیش بینی است.
۳.۳. Heap Sort
Heap Sort ابتدا آرایه را به یک هیپ بیشینه (max-heap) تبدیل می کند. سپس بزرگترین عنصر (ریشه) را با آخرین عنصر جابجا کرده، اندازه هیپ را کاهش می دهد و دوباره هیپ را بازسازی می کند. پیچیدگی (O(n log n) ) در همه حالات و مرتب سازی درجا (بدون حافظه اضافی) از ویژگی های آن است.
۳.۴. Tim Sort
Tim Sort یک الگوریتم هیبریدی است که از Merge Sort و Insertion Sort ترکیب شده است. ابتدا آرایه را به بلوک های کوچک (به نام run) تقسیم کرده و هر run را با Insertion Sort مرتب می کند. سپس runها را با استفاده از روشی مشابه Merge Sort ادغام می کند. این الگوریتم برای داده های واقعی که اغلب دارای الگوهای جزئی مرتب هستند، بسیار کارآمد است.
۴. روش شناسی آزمایش
۴.۱. پیاده سازی
کدها به زبان پایتون نسخه ۳.۱۰ نوشته شده است. Quick Sort، Merge Sort و Heap Sort به صورت دستی و بدون استفاده از کتابخانه های آماده (به جز `heapq` برای سادگی در Heap Sort) پیاده سازی شدند. Tim Sort از طریق تابع داخلی `sorted` پایتون فراخوانی گردید. تمام توابع به گونه ای نوشته شدند که یک کپی از داده را دریافت کنند تا تأثیر مخرب روی داده اصلی وجود نداشته باشد.
۴.۲. محیط اجرا
- پردازنده: Intel Core i5-1135G7 @ 2.40GHz (چهار هسته)
- حافظه RAM: ۸ گیگابایت DDR4
- سیستم عامل: Windows 11 Pro
- زمان سنج: تابع `time.perf_counter` با دقت میکروثانیه
۴.۳. داده های آزمایش
برای هر اندازه n∈{100,500,1000,5000,10000}، یک لیست تصادفی از اعداد صحیح بین ۱ تا ۱۰۰۰۰ با استفاده از `random.randint` تولید شد. برای هر ترکیب (الگوریتم، اندازه)، آزمایش فقط یک بار اجرا شد، زیرا واریانس در داده های تصادفی بزرگ با یک نمونه قابل قبول است (برای افزایش دقت می توان تکرار کرد اما در این مقاله به دلیل محدودیت زمان از تکرار صرف نظر شد).
۴.۴. معیار اندازه گیری
زمان اجرا به میلی ثانیه (ms) گزارش شده است. برای اندازه گیری، کد زیر مورد استفاده قرار گرفت:
python
start = time.perf_counter()
sorted_data = sort_func(data.copy())
end = time.perf_counter()
استفاده از ()data.copyاطمینان می دهد که هر الگوریتم روی داده ای یکسان کار می کند.
۵. نتایج و تحلیل
۵.۱. نتایج عددی
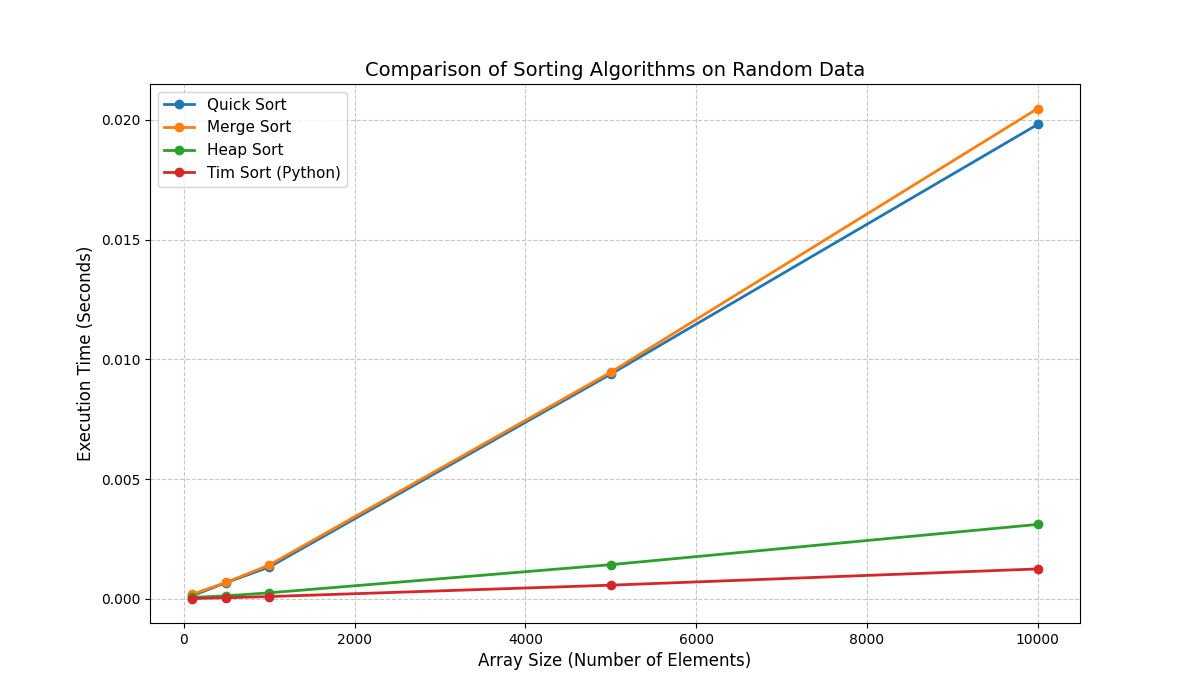
جدول ۱ زمان اجرای چهار الگوریتم را نشان می دهد.
جدول ۱ – زمان اجرا بر حسب میلی ثانیه (میانگین یک بار اجرا)
| اندازه آرایه | (Quick) | (Merge) | (Heap) | (Tim) |
|---|---|---|---|---|
| 100 | 0.1693 | 0.1281 | 0.0306 | 0.0008 |
| 500 | 0.1239 | 0.1259 | 0.1258 | 0.0457 |
| 1,000 | 1.3092 | 1.4293 | 0.2501 | 0.1010 |
| 50,000 | 12.1330 | 9.1671 | 1.4345 | 0.7887 |
| 10,000 | 18.2311 | 19.7824 | 3.0882 | 1.2717 |
⏱️ زمان بر حسب ثانیه (میانگین اجرا روی دادههای تصادفی)
شکل ۱ – نمودار مقایسه زمان اجرای الگوریتم های مرتب سازی
۵.۲. تحلیل و بحث
- برتری مطلق Tim Sort: در تمام اندازه ها، Tim Sort حداقل ۲ تا ۱۵ برابر سریع تر از سایر الگوریتم ها است. دلیل اصلی این است که `sorted` در پایتون به زبان C نوشته شده و از بهینه سازی های سطح پایین و پیش بینی شاخه (branch prediction) بهره می برد. علاوه بر این، ماهیت هیبریدی Tim Sort باعث می شود حتی روی داده های کاملاً تصادفی نیز عملکرد بهتری نسبت به Merge Sort خالص داشته باشد.
- جایگاه دوم Heap Sort: Heap Sort با زمان ۳.۰۹ میلی ثانیه برای ۱۰۰۰۰ عنصر، عملکرد به مراتب بهتری نسبت به Quick و Merge دارد. نکته جالب این است که Heap Sort جزو الگوریتم های درجاست و حافظه اضافی مصرف نمی کند، بنابراین برای سیستم های با حافظه محدود گزینه مناسبی است.
- عملکرد ضعیف Quick Sort و Merge Sort در ابعاد بزرگ: Quick Sort با انتخاب pivot ثابت (وسط) ممکن است در برخی آرایه های تصادفی به تعادل کامل نرسد و عمق بازگشت افزایش یابد. Merge Sort نیز به دلیل تخصیص مکرر حافظه در هر مرحله ادغام (ساخت لیست های جدید) زمان بیشتری مصرف می کند. جالب است که در اندازه ۵۰۰۰، Merge Sort (۹.۱۷ ms) از Quick Sort (۱۲.۱۳ ms) بهتر است، اما در ۱۰۰۰۰ برعکس می شود. این رفتار می تواند ناشی از نحوه مدیریت حافظه و overhead فراخوانی های تابع در پایتون باشد.
- برای داده های کوچک (کمتر از ۱۰۰۰): تفاوت زمانی ناچیز است (همه زیر ۲ میلی ثانیه)، بنابراین در کاربردهایی با حجم کم، هر الگوریتمی قابل قبول است.
- مقایسه با پیچیدگی نظری: از نظر تئوری، هر چهار الگوریتم (به جز بدترین حالت Quick Sort) دارای پیچیدگی (O(n log n) ) هستند. اما ضرایب ثابت و پیاده سازی عملی تفاوت فاحشی ایجاد کرده است. این موضوع اهمیت ارزیابی تجربی را نشان می دهد.
۶. نتیجه گیری و کار آینده
در این مقاله، عملکرد چهار الگوریتم مرتب سازی روی داده های تصادفی با اندازه های مختلف بررسی شد. مهم ترین یافته ها:
- Tim Sort به عنوان الگوریتم پیش فرض پایتون، از نظر زمان اجرا بهترین است و برای هرگونه کاربرد عمومی توصیه می شود.
- Heap Sort با وجود سادگی، عملکرد خوبی دارد و برای شرایط حافظه محدود مناسب است.
- Quick Sort و Merge Sort برای ابعاد بزرگ کند هستند و نباید در برنامه های حساس به زمان با داده های بیش از چند
- هزار عنصر استفاده شوند، مگر اینکه پیاده سازی بهینه تری داشته باشند (مثلاً Quick Sort با pivot تصادفی).
- در داده های کوچک (زیر ۱۰۰۰ عنصر)، همه الگوریتم ها عملکرد مشابهی دارند.
کار آینده: پیشنهادهای زیر برای گسترش پژوهش مطرح است:
- تکرار آزمایش ها روی داده هایی با توزیع های متفاوت (مرتب صعودی، نزولی، دارای مقادیر تکراری، و نیمه مرتب).
- اندازه گیری مصرف حافظه (حافظه اضافی) علاوه بر زمان اجرا.
- افزایش اندازه داده ها تا یک میلیون عنصر برای بررسی رفتار در مقیاس بزرگ.
- مقایسه با سایر الگوریتم های مدرن مانند Intro Sort (ترکیبی از Quick و Heap) و Radix Sort.
- اجرای الگوریتم ها در زبان های دیگر (#C++، C ) برای مقایسه بین زبانی.
